Last Updated 20 Jan 2022 Difficulty level : Advanced

Access security was very weak in all MDB versions up to 2003 but was significantly improved since the introduction of the ACCDB format in version 2007
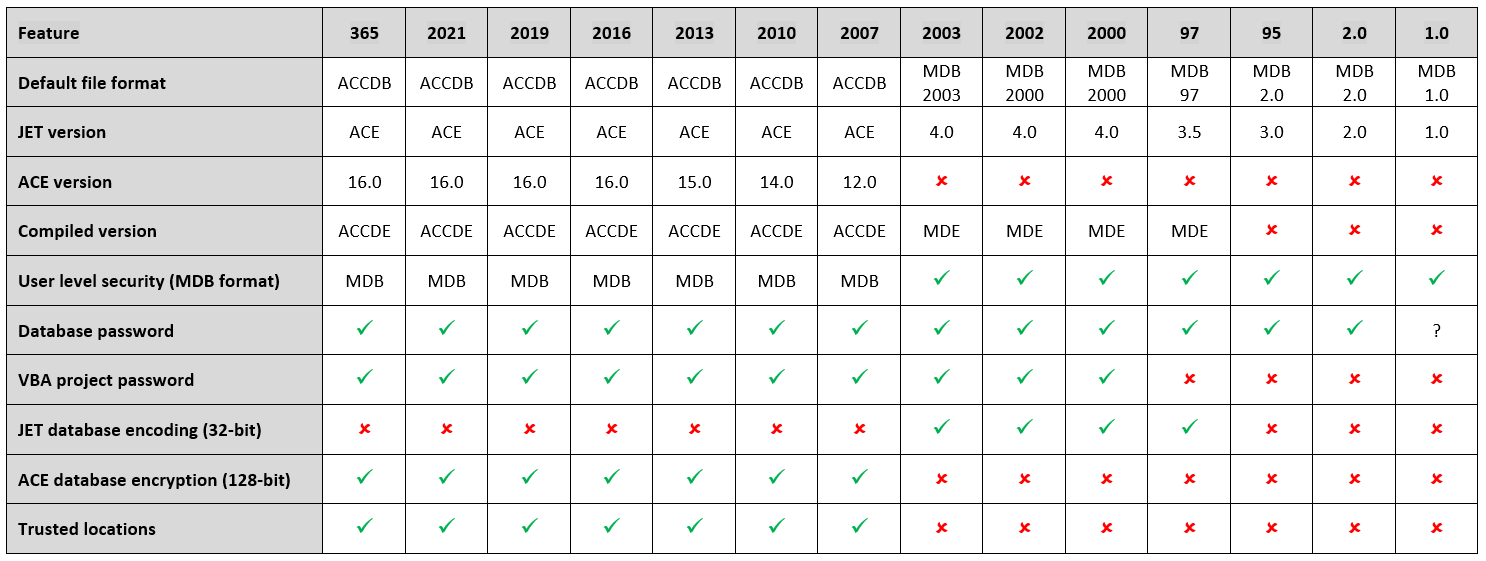
Access Security by Version Page 3 (of 3)
Access 1.0 / 2.0
• User level (workgroup) security & permissions for each object (easy to bypass)
• Database password at Access program level only
Apply a password to one file & its required on all files/ remove it from one file and its needed on none.
• Code cannot be password protected
• No MDE files
Access 95
• Database password set for individual MDB files
Access 97
• Whole database encoding (AKA encryption) (32-bit)
• Compiled version (MDE format) added
Access 2000 / 2002 / 2003
• VBA project password added
Access 2007 onwards
• Trusted locations
• Strong 128-bit encryption
• Compiled version uses ACCDE format
• User level (workgroup) security dropped for ACCDB files
Password protection / encryption
The following explanation of password protection / encryption is taken from the EverythingAccess website.
Access World Forums member The_Doc_Man (Richard W Hunt Jr) has kindly provided a very clear explanation of what each statement means
Jet 3: The database password, when set, is stored as plain text in the MDB file header.
Anyone can quickly find the password using a text editor such as Notepad since the header is early in the file.
Jet 4: The database password, when set, is obfuscated with a simple XOR pattern algorithm based on the file creation date/time (stored inside the file) which is then stored in the MDB file header.
Anybody with a hex editor can manually find two things: The binary file creation date & time and the password and can figure out the password as long as they understand XOR. Both of those things are in the header so it wouldn't take long to find them.
Jet 3 AND 4: The MDB file header itself is further obfuscated with an XOR pattern – although its a constant XOR stream this time.
The file header's encryption is a simple XOR pattern. If you know other things that should be in the header and know them in clear text, you can probably work backwards or write a VERY simple algorithm to decrypt the header. Because the XOR pattern will even encrypt 0 - and in the process will give you the inverse of the XOR key.
ACCDB files: The password is no longer stored as obfuscated plain text in the file header. Instead, a hash is used to check that the user has entered the valid password. The hash is generated from a combination of RC4 and SHA-1 algorithms.
The hash-checking algorithm is based on the same technology that gives you digital signatures. In essence, a signature is a polynomial (in binary, of course) based on some obscure formula that gives you a long string of bits by multiplying two numbers together in some orderly pattern. When you complete the multiplication you have a hash (which in math is sometimes called a "characteristic") that depends on the contents of the thing you were trying to sign. It doesn't matter whether the thing being protected is short or long. When you attach the hash value as part of the item you have signed the item in a way that is very difficult to spoof. If you send the hash in a separate signature file, your recipient can confirm your identity.
In general, if you have a 128 bit hash, that hash sequence has 2^128 possible values, which is roughly 512 * ( 10^36 ). So the odds of accidentally generating the same hash value from two different inputs SHOULD be 1 divided by that number, which is pretty small - something like 0.2 * ( 10^ -38 ).
There are ways to determine how big a file has to get before that probability gets big enough to even worry about. But the point is, if you store the HASH of something and then later input that something again, you can't compare the something - but you CAN compute the HASH of something and compare it to the stored hash. If the hashes match, the inputs probably also matched.
Now, the only other two things that might be confusing is that RC4 and SHA-1 are two popular hash-generating algorithms. Each is based on a different polynomial. So if you enter a password and BOTH of the resulting two hashes match the stored hashes, you are fairly sure that the right thing was entered. After that, the database decryption key can be generated from the password.
Why is this any better than simply obscuring the password? (You might ask?) Because the hash computation is one-way. It is irreversible. The fact that the hash is of a fixed length means that if an overflow occurs out of the high-order bit of the hash slot, bits get lost and without those lost bits, you have a very large number of possible solutions to the polynomial. Not QUITE infinite since the inputs had to be finite - but it is a REALLY BIG number of possible solutions.
Feedback
Please use the contact form below to let me know whether you found this article useful or if you have any questions.
Please also consider making a donation towards the costs of maintaining this website. Thank you
Colin Riddington Mendip Data Systems Last updated : 20 Jan 2022
Return to Access Articles
Page 3 of 3
1
2
3
Return To Top
|
|
|