
Finding Unmatched Records
First Published 15 Dec 2022 Difficulty level : Moderate
This is the twelfth in a series of articles discussing various tests done to compare the efficiency of different approaches to coding.
This article was written in response to a recent thread posted at Access World Forums Query runs slow with NOT IN which discussed the speed of three different approaches to identifying unmatched records between two tables and the reasons for those speed differences.
The different methods discussed were:
a) Subquery using NOT IN
b) Subquery using NOT EXISTS
c) Unmatched query using IS NULL
It would be fair to say that the exchange led to some strong disagreements in opinion between another forum member and myself. In order to provide evidence based on facts, I created this speed comparison test using the same dataset based on UK postcodes as was used in an earlier speed test: Check Record Exists
The test database used is available for download later in this article for anyone who wishes to try this for themselves
The query SQL for each test was as follows:
a) Query qryNotIN
SELECT tblData.Postcode
FROM tblData
WHERE tblData.Postcode NOT IN (SELECT tblSource.Postcode FROM tblSource);
b) Query qryNotEXISTS
Originally I saved this query as
SELECT tblData.Postcode
FROM tblData
WHERE NOT Exists (SELECT NULL FROM tblSource WHERE tblSource.Postcode = tblData.Postcode);
Access then proceeded to rewrite this in a way it deemed more efficient!
SELECT tblData.Postcode
FROM tblData
WHERE (Exists (SELECT NULL FROM tblSource WHERE tblSource.Postcode = tblData.Postcode))=False;
I tested both. The times were almost identical in each case!
c) Query qryUnmatched
SELECT tblData.Postcode
FROM tblData LEFT JOIN tblSource ON tblData.[Postcode] = tblSource.[Postcode]
WHERE (((tblSource.Postcode) Is Null));
There are two similar versions of this set of speed tests.
The main difference is the search field is NOT INDEXED in one and INDEXED in the other.
In a real world application, fields being searched regularly should ALWAYS be INDEXED.
The index will increase file size but dramatically reduce search times.
Access looks up the location of the data in the index so it can be retrieved very quickly in a query or SQL statement.
All searches that can use indexes will be faster but there are some other interesting differences in the results for each version.
In each of these tests, a 'reference' table tblSource containing 10,000 different UK postcodes (deliberately kept small to reduce file size) is used to populate the test table tblData which is initially empty.
One RANDOM record is then replaced by a 'dummy' postcode 'XM4 5HQ' used in the record check.
For info, this dummy UK postcode is used to sort letters addressed to Santa Claus!!!
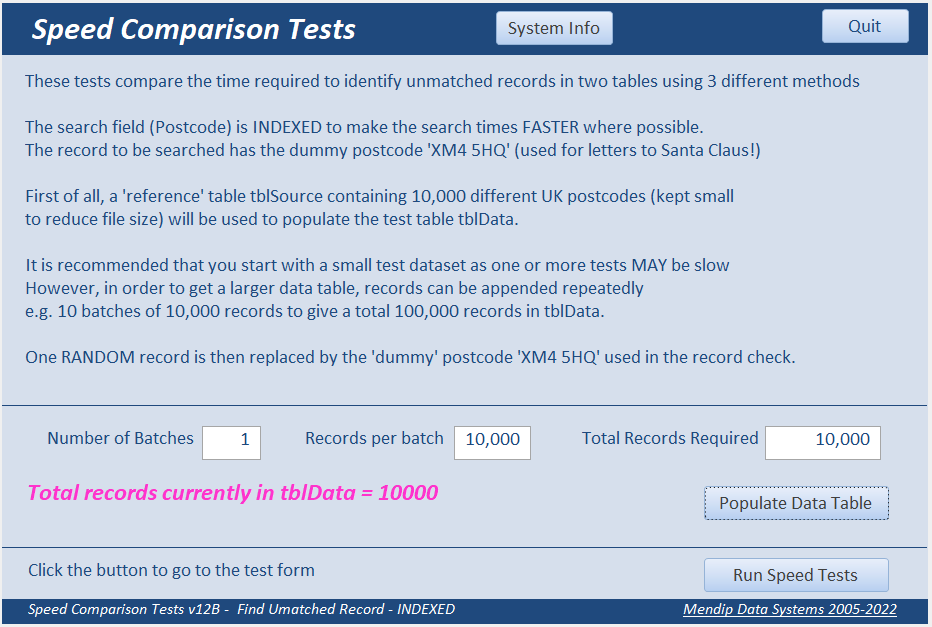
Once the data table has been populated, click the Run button to start running the tests.
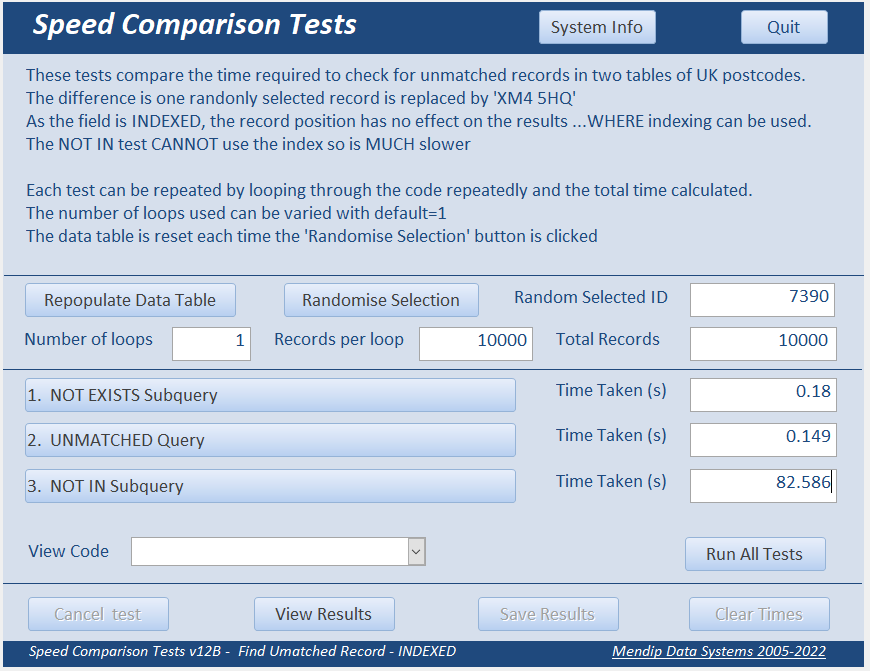
I ran each set of tests 10 times, randomising the position of the unmatched dummy postcode each time.
Repeating the tests minimizes the effect of natural variation in times depending on CPU load etc.
However, the results for each type of test were fairly consistent in each case. For example
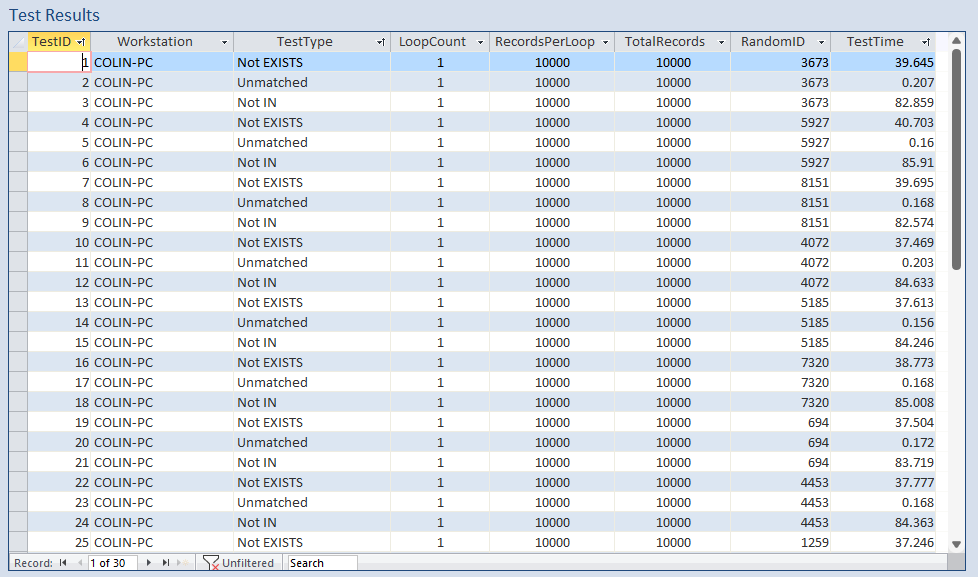
A summary of the test results is also created with the minimum, maximum, average and standard deviation displayed for each test
Here is the results summary for the non-indexed tables:

As can be clearly seen, the two subquery methods are both very slow though the NOT IN query is far slower than NOT EXISTS.
By comparison, the simple unmatched query created using the query wizard is blisteringly fast!
For comparison, here is the results summary for the indexed tables:

The differences from the first set of tests are interesting:
a) The NOT IN query is as slow as before indicating that it cannot make use of the indexing
b) The NOT EXISTS query is now very fast indicating that it does use indexing
c) The unmatched query is still (just) the fastest though indexing appears to play little part in this set of results.
Subqueries are a very useful tool for any developer to use and, in many cases, these are the best method to use for complex tasks.
For example, Allen Browne has a excellent article Subquery basics showing some of the things that are possible using subqueries
However, my experience over many years of working with subqueries is that they are generally less efficient and therefore slower than well-designed standard queries designed to do the same job. This remains true whether or not indexing is used
In this case. the NOT EXISTS subquery does work well for indexed fields but it is more complex to create and still slower than a simple unmatched query.
I see no benefit in using subqueries for this purpose
NOTE:
Unfortunately, it isn't possible to view the query execution plans for subqueries in Access, so it isn't possible to use the hidden JET SHOWPLAN feature to determine exactly how Access processes subqueries.
The test database also allows you to test with a larger dataset. To do so, the postcode records can be appended repeatedly
For example, with the indexed version of the tables, I used 100 batches of 10,000 records to give a total of 1,000,000 records in tblData.
The greater efficiency of the simple unmatched query became even more apparent in this case with the unmatched query now taking just under 75% of the time taken by NOT EXISTS

I didn't attempt to time the NOT IN query for this large dataset for what, I hope, are obvious reasons.
Finally, I repeated those two tests using 10 million records in tblData. The average results in this case are shown below

In both cases, the total time is about 9x larger and the time difference is therefore even more significant
NOTE:
You will be warned that it will take a long time to populate the data table with such a large dataset
Conclusions
A NOT IN subquery is a very inefficient method of finding unmatched records as it cannot use indexes.
By comparison, a NOT EXISTS subquery is far better as it does use indexes
However, an unmatched query (such as that created by the wizard) is more efficient (faster) than either type of subquery
This becomes even more noticeable with larger datasets.
Download
Click to download the INDEXED or NON-INDEXED versions of the test database
CheckUnmatchedRecords - INDEXED Approx 1.9 MB (zipped)
CheckUnmatchedRecords - NOT INDEXED Approx 1.75 MB (zipped)
Feedback
Please use the contact form below to let me know whether you found this article useful or if you have any questions/comments.
Do let me know if there are any errors
Please also consider making a donation towards the costs of maintaining this website. Thank you
Colin Riddington Mendip Data Systems Last Updated 15 Dec 2022
Return to Speed Test List
Page 12
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Return to Top