
HAVING vs WHERE
Originally written 27 Feb 2019 Last Updated 16 Feb 2022 Difficulty level : Moderate
Section Links:
Patients Data
Postcodes Data
Conclusions
This is the fourth in a series of articles discussing various tests done to compare the efficiency of different approaches to coding.
Example databases are provided in each case so the same tests can be done on your own workstations
This is an updated version of an article originally written in Feb 2019 in response to a thread Desperate-Count Help Needed at Access World Forums from 2018.
The forum thread included discussion of the efficiency of aggregate queries using a WHERE clause compared to those using a HAVING clause.
HAVING:
SELECT field1, Sum(field2)
FROM table
GROUP BY field1
HAVING field 1 = something
WHERE:
SELECT field1, Sum(field2)
FROM table
WHERE field 1 = something
GROUP BY field1
For those unaware of what difference this makes, fellow AWF moderator Galaxiom explained these as below:
The first one (HAVING) is what the Access query designer encourages a novice to build.
The second (WHERE) is what the query should be.
The difference is that the WHERE is applied before the GROUP BY while the HAVING is applied after.
The first query will group all the records then only return the Having.
The second query selects only the "something" records and the Group becomes trivial.
I agreed totally with what was written by Galaxiom in that post.
I decided to adapt my speed comparison test utility to demonstrate evidence of this point for future use.
However, the initial results I obtained were nothing like as clear cut as I had expected so I did two further tests with different datasets.
1. Patients Return To Top
I adapted the dataset from my Patient Login (Kiosk Mode) example app for this test.
I imported the same 3300 records 9 times over to give a dataset of around 30000 records.
Duplicating patient names and dates of birth doesn’t matter for these tests.
Each record includes fields for gender & date of birth (both indexed).
Click to download the database used for this test : Speed Comparison Test - Having/Where v6.2 Approx 3.3 MB (zipped)
Code was used to count the number of records, grouping by birth day & birth month as well as gender and these record counts were appended to another table.
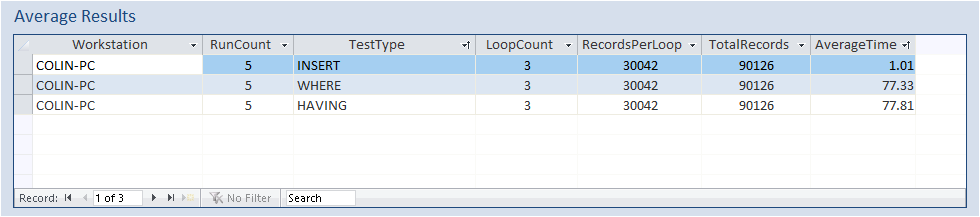
The tests each created just over 700 records on each run. The code looped through each run 3 times in each test
All tests were repeated 5 times and average values calculated
THREE different tests were run on this dataset:
a) HAVING - data is first grouped then filtered, counted and appended one at a time
For I = 1 To LC 'loop count
For M = 1 To 12 'month count
For D = 1 To 31 'day count
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS CountOfPatientID, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), Month([DOB]), Day([DOB])" & _
" HAVING (((Month([DOB]))=" & M & ") AND ((Day([DOB]))=" & D & "));"
Next D
Next M
Next I
b) WHERE – data is first filtered then grouped, counted and appended one at a time
For I = 1 To LC 'loop count
For M = 1 To 12 'month count
For D = 1 To 31 'day count
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS CountOfPatientID, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" WHERE (((Month([DOB]))=" & M & ") AND ((Day([DOB]))=" & D & "))" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), Month([DOB]), Day([DOB]);"
Next D
Next M
Next I
c) INSERT – data is grouped then all records were appended ‘at once’
For I = 1 To LC 'loop count
db.Execute "INSERT INTO tblData ( RecordCount, BirthDateMonth, Gender )" & _
" SELECT Count(tblPatients.PatientID) AS RecordCount, Left([DOB],5) AS BirthDateMonth, tblPatients.Gender" & _
" FROM tblPatients" & _
" GROUP BY Left([DOB],5), tblPatients.Gender, Day([DOB]), Month([DOB])" & _
" ORDER BY tblPatients.Gender, Left([DOB],5);"
Next I
In these tests using WHERE was faster than using HAVING but the difference between them was negligible.
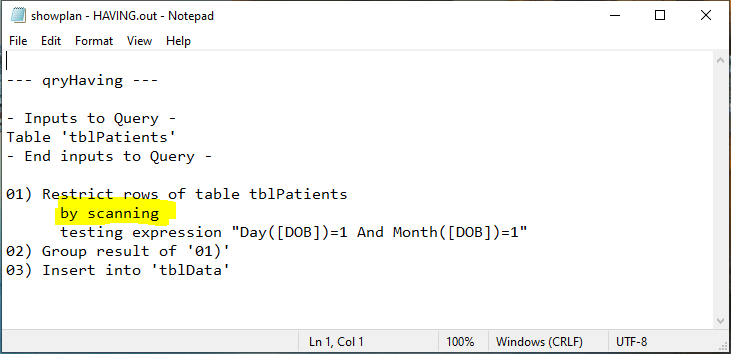
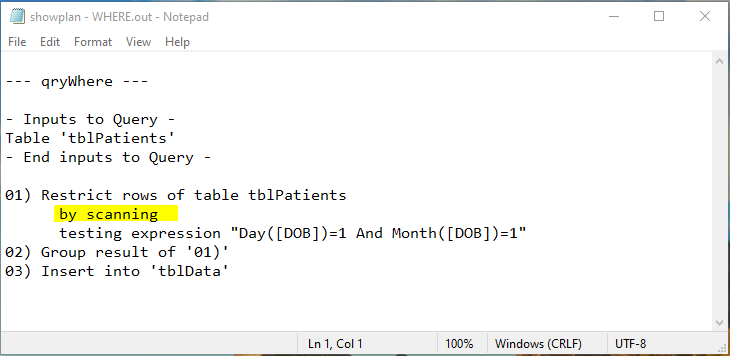
I tested the query execution plans for each using the relatively little known JET ShowPlan feature
NOTE:
For more information about the JET ShowPlan feature, see my article: Show Plan . . . Run Faster
HAVING
|
WHERE
|
As you can see, the query execution plans were identical. In both cases, the full dataset was being scanned by Access.
Whilst that explained the very similar times obtained, at that stage I didn't understand the reasons for this . . . but see later.
Using INSERT is of course dramatically faster than either of the other 2 methods as it all happens 'at once' rather than 'row by agonising row' (RBAR) as in a recordset loop.
For information, I also tested 4 different versions of the HAVING tests to compare the relative efficiency of each. The measured times were VERY different
Method 1 (as above) - using Month & Day functions - approx. 78s for 3 loops
For I = 1 To LC 'loop count
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS RecordCount, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), Month([DOB]), Day([DOB])" & _
" HAVING (((Month([DOB]))=" & M & ") AND ((Day([DOB]))=" & D & "));"
Next I
Method 2 - as method 1 and formatting dates by mm/dd/yyyy - approx. 298s for 3 loops
For I = 1 To LC 'loop count
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS RecordCount, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), Month(Format([DOB],'mm/dd/yyyy')), Day(Format([DOB],'mm/dd/yyyy'))" & _
" HAVING (((Month(Format([DOB],'mm/dd/yyyy')))=" & M & ") AND ((Day(Format([DOB],'mm/dd/yyyy')))=" & D & "));"
Next I
Method 3 - using Left & Mid functions - approx. 170s for 3 loops
For I = 1 To LC 'loop count
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS RecordCount, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), Mid([DOB],4,2), Left([DOB],2)" & _
" HAVING ((Int(Mid([DOB],4,2))=" & M & ") AND (Int(Left([DOB],2))=" & D & "));"
Next I
Method 4 - using Date Part functions – approx. 160s for 3 loops
For I = 1 To LC 'loop count
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS RecordCount, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), DatePart('m',[DOB]), DatePart('d',[DOB])" & _
" HAVING ((DatePart('m',[DOB])=" & M & ") AND (DatePart('d',[DOB])=" & D & "));"
Next I
I have since investigated the cause of these differences as part of my Optimising Queries article.
2. Postcodes Return To Top
For the second test, I used my Postcodes table from the UK Postal Address Finder application with 2.6 million records.
Unfortunately, I cannot attach the database used as the large dataset is 240 MB in size
The number of postcodes for selected areas, districts, sectors & zones were counted and the results appended to a data table.
There are around 700 aggregated records created
This was done in 2 ways:
a) HAVING - data is grouped then filtered, counted & added to the data table one at a time
For I = 1 To LC 'loop count
db.Execute "INSERT INTO PostcodesCount ( TotalPostcodes, PostcodeArea, PostcodeDistrict, PostcodeSector, PostcodeZone )" & _
" SELECT Count(Postcodes.ID) AS CountOfID, Postcodes.PostcodeArea, Postcodes.PostcodeDistrict,
Postcodes.PostcodeSector, Postcodes.PostcodeZone" & _
" FROM Postcodes" & _
" GROUP BY Postcodes.PostcodeArea, Postcodes.PostcodeDistrict, Postcodes.PostcodeSector,
Postcodes.PostcodeZone, Postcodes.InUse, Postcodes.Introduced" & _
" HAVING (((Postcodes.InUse)=True) AND ((Year([Introduced])) Between 1985 And 1996));"
Next I
b) WHERE - data is filtered then grouped, counted & added one at a time
For I = 1 To LC 'loop count
db.Execute "INSERT INTO PostcodesCount ( TotalPostcodes, PostcodeArea, PostcodeDistrict, PostcodeSector, PostcodeZone )" & _
" SELECT Count(Postcodes.ID) AS CountOfID, Postcodes.PostcodeArea, Postcodes.PostcodeDistrict,
Postcodes.PostcodeSector, Postcodes.PostcodeZone" & _
" FROM Postcodes" & _
" WHERE (((Postcodes.InUse)=True) AND ((Year([Introduced])) Between 1985 And 1996))" & _
" GROUP BY Postcodes.PostcodeArea, Postcodes.PostcodeDistrict, Postcodes.PostcodeSector, Postcodes.PostcodeZone;"
Next I
The tests were each run 10 times and the average calculated for each test
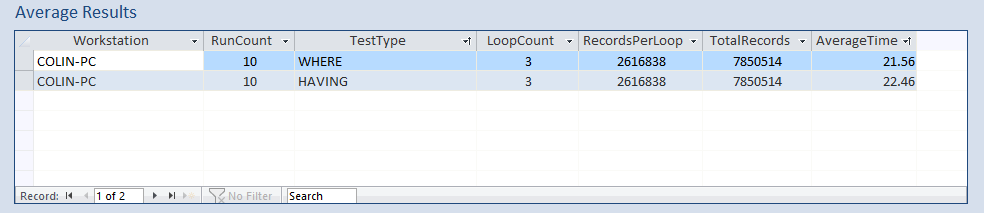
Using WHERE was slightly faster but the difference in times was relatively small
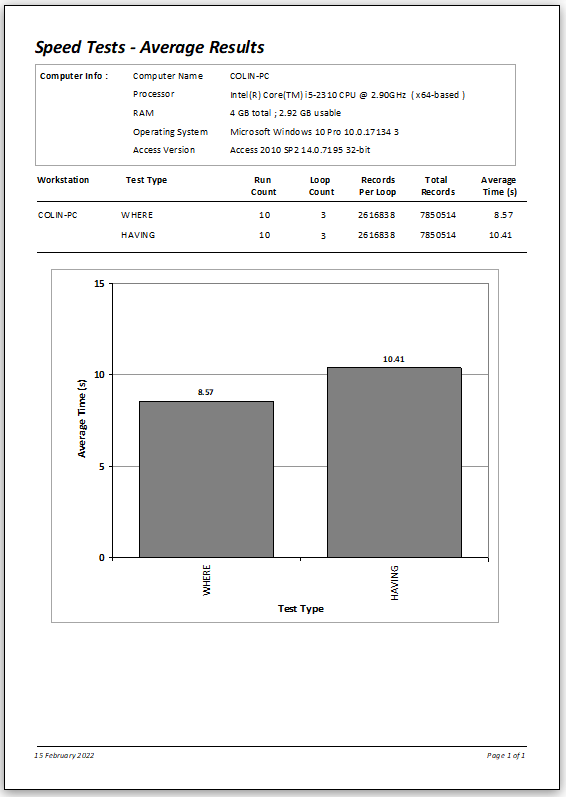
Here are the results as a report:
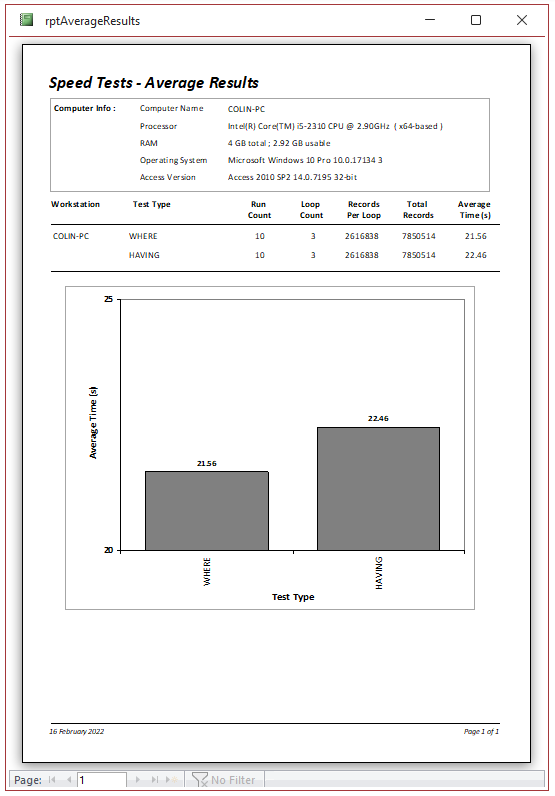
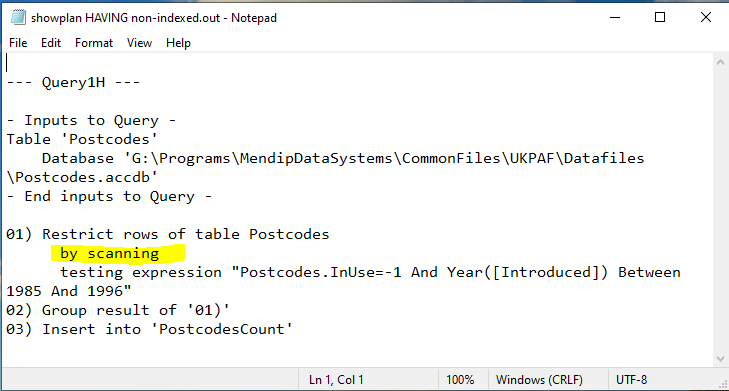
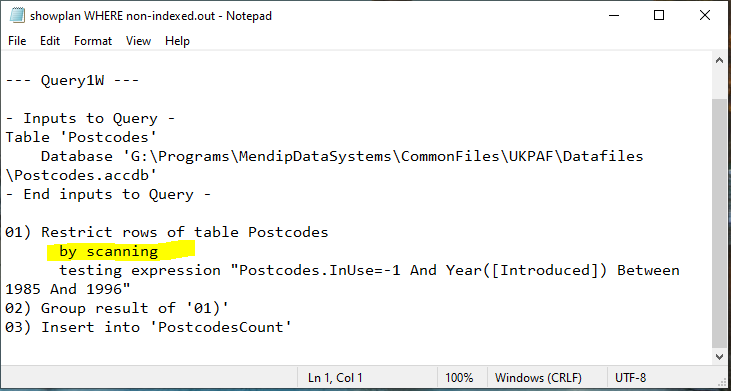
Once again I tested the query execution plans for each using the JET ShowPlan feature
HAVING
|
WHERE
|
Once again, the query execution plans were identical. In both cases, the full dataset was being scanned by Access.
It was at this point that I belatedly realised that the tests were flawed due to the use of the date filter: Between 1985 And 1996
Although the date field was INDEXED, the filter criteria used meant that Access was unable to use the index thus resulting in a full dataset scan.
I amended the query filter to: Between #1/1/1985# And #12/31/1996#. Doing this allowed Access to USE the indexing on the date field
The amended queries were as follows:
a) HAVING
For I = 1 To LC 'loop count
db.Execute "INSERT INTO PostcodesCount ( TotalPostcodes, PostcodeArea, PostcodeDistrict, PostcodeSector, PostcodeZone )" & _
" SELECT Count(Postcodes.ID) AS CountOfID, Postcodes.PostcodeArea, Postcodes.PostcodeDistrict,
Postcodes.PostcodeSector, Postcodes.PostcodeZone" & _
" FROM Postcodes" & _
" GROUP BY Postcodes.PostcodeArea, Postcodes.PostcodeDistrict, Postcodes.PostcodeSector,
Postcodes.PostcodeZone, Postcodes.InUse, Postcodes.Introduced" & _
" HAVING (((Postcodes.InUse)=True) AND ((Postcodes.Introduced) Between #1/1/1985# And #12/31/1996#));"
Next I
b) WHERE
For I = 1 To LC 'loop count
db.Execute "INSERT INTO PostcodesCount ( TotalPostcodes, PostcodeArea, PostcodeDistrict, PostcodeSector, PostcodeZone )" & _
" SELECT Count(Postcodes.ID) AS CountOfID, Postcodes.PostcodeArea, Postcodes.PostcodeDistrict,
Postcodes.PostcodeSector, Postcodes.PostcodeZone" & _
" FROM Postcodes" & _
" WHERE (((Postcodes.InUse)=True) AND ((Postcodes.Introduced) Between #1/1/1985# And #12/31/1996#))" & _
" GROUP BY Postcodes.PostcodeArea, Postcodes.PostcodeDistrict, Postcodes.PostcodeSector, Postcodes.PostcodeZone;"
Next I
Once again, the tests were each run 10 times and the average calculated for each test
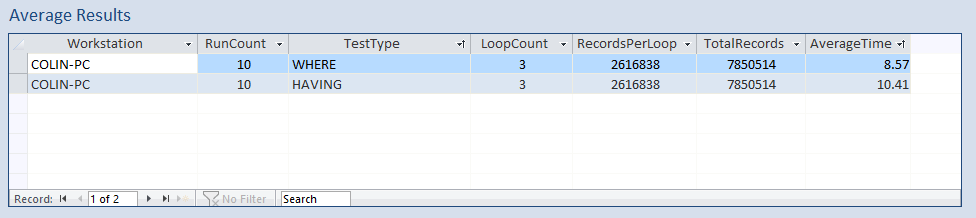
Both sets of results were faster due to the use of indexing. However, the improvement was particularly significant using WHERE.
On average, the execution time was almost 18% faster using WHERE compared to HAVING.
Here are the results as a report:
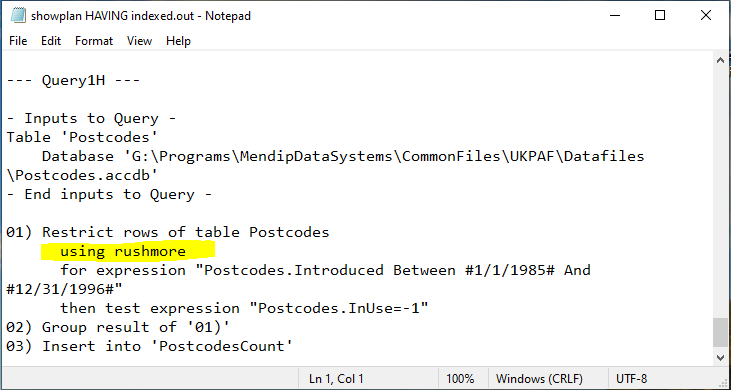
I again tested the query execution plans for each using the JET ShowPlan feature
HAVING
|
WHERE
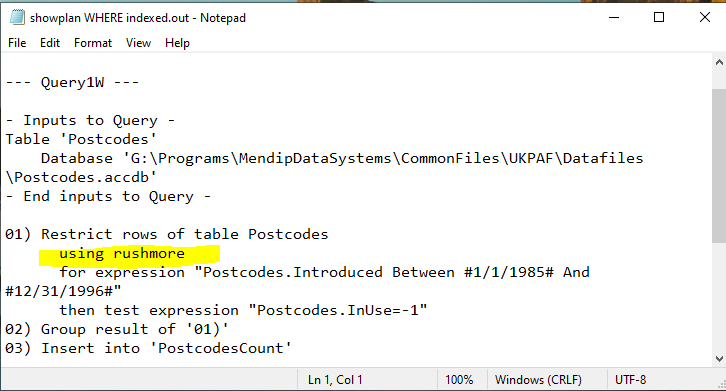
|
In both cases, the query execution plans included the phrase 'using Rushmore'.
Rushmore is the code name for the query optimisation technology that Access uses to speed up query execution when using indexed fields.
Further Reading:
For more information about the JET ShowPlan feature, see my article: Show Plan . . . Run Faster
I also recommend an excellent article written by Mike Wolfe on his NoLongerSet website: JetShowPlan - A Primer
3. Conclusions Updated 16 Feb 2022
Return To Top
These tests were originally done to provide evidence that the use of HAVING is far less efficient and therefore slower than using WHERE in aggregate queries.
However, the initial results were nothing like I had expected with little difference between the times for HAVING and WHERE.
This was due to the full dataset being scanned in each case.
Further testing showed clearly the need to use indexing correctly.
When this is applied, using WHERE is indeed far faster than using HAVING as Access is then able to make use of the Rushmore query optimisation technology.
This subject is discussed in more detail in another article in this series: Optimising Queries
This thread at Stackoverflow also discusses the same topic with reference to query execution plans.
4. Feedback Return To Top
Please use the contact form below to let me know whether you found this article useful or if you have any questions/comments.
I would appreciate feedback on the tests themselves together with any suggested improvements or alterations to the process.
Please also consider making a donation towards the costs of maintaining this website. Thank you
Colin Riddington Mendip Data Systems Last Updated 16 Feb 2022
Return to Speed Test List
Page 4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Return to Top
|
|
|