
Check Record Exists
First Published 27 Feb 2019 Last Updated 17 Feb 2023 Difficulty level : Moderate
Section Links:
Indexing
Test Code
Search field Not Indexed
Indexed Search field
Downloads
Feedback
This is the seventh in a series of articles discussing various tests done to compare the efficiency of different approaches to coding.
Example databases are provided in each case so the same tests can be done on your own workstations
These tests compare the time required to check the existence of a specified record in a large data table using 7 different methods. This was originally done as a follow up to an example database uploaded at Utter Access forum by David Marten, AKA cheekybuddha, in the thread VBA - Search Value In Table
UPDATED 17 Feb 2023
This is a significantly updated version with 3 additional tests and changes to the code to make the loops run more efficiently.
Many thanks to ex-MVP Josef Pötzl for suggesting several improvements to this article.
1. Indexing Return To Top
There are two similar versions of this set of speed tests.
The main difference is the search field is NOT INDEXED in one and INDEXED in the other.
In a real world application, fields being searched regularly should ALWAYS be INDEXED.
The index will increase file size but dramatically reduce search times.
Access looks up the location of the data in the index so it can be retrieved very quickly in a query or SQL statement.
INDEXING makes all searches much faster but there are some other interesting differences in the results for each version.
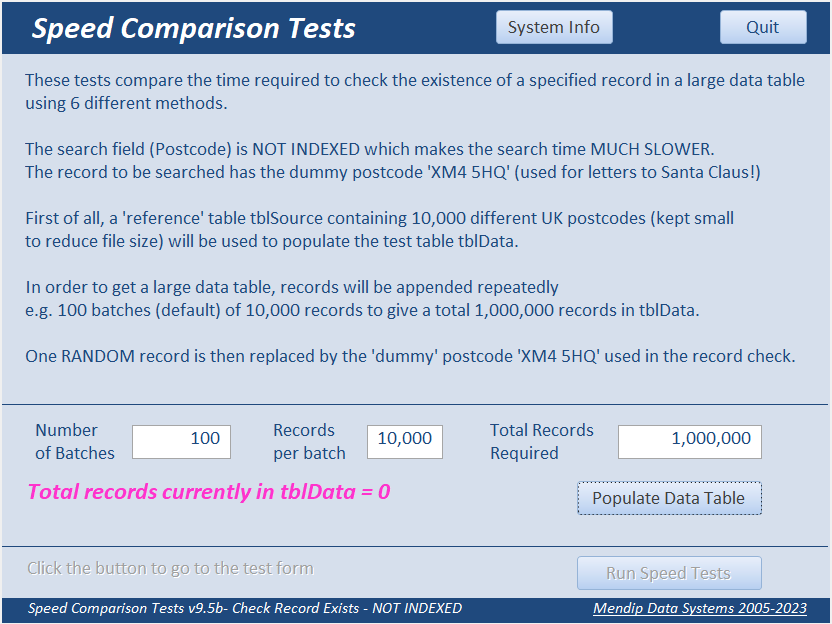
In each of these tests, a 'reference' table tblSource containing 10,000 different UK postcodes (deliberately kept small to reduce file size) is used to populate the test table tblData which is initially empty.
In order to get a large data table, those records are appended repeatedly
For example, 100 batches (default) of 10,000 records to give a total 1,000,000 records in tblData.
One RANDOM record is then replaced by a 'dummy' postcode 'XM4 5HQ' used in the record check.
For info, this postcode is used to sort letters addressed to Santa Claus!!!
Once the data table has been populated, click the Run button to start running the tests.
The recordset is then looped through repeatedly, exiting each loop as soon as the search postcode is found, and the total time required is measured.
NOTE:
The applications have been set to compact automatically when closed to reduce file 'bloat'.
This does carry a small risk of corruption so you may wish to create a backup copy or disable automatic compacting.
However, I haven’t experienced any issues during repeated testing with these applications.
2. Test Code Return To Top
The 7 methods being compared are :
a) DLookup
b) DCount
c) SQL Count(*)
d) SQL SELECT
e) EXISTS
d) SELECT TOP 1
d) SEEK (Indexed version ONLY)
The code used for each test is as follows:
a) DLookup
For Q = 1 To LC 'loop count
'look for matching record
blnRet = Not IsNull(DLookup("ID", "tblData", "Postcode = 'XM4 5HQ'"))
If blnRet Then GoTo NextStep
If blnCancel Then GoTo EndRoutine
NextStep:
blnRet = False
Next Q
b) DCount
For Q = 1 To LC 'loop count
'check for non-zero count
blnRet = DCount("ID", "tblData", "Postcode = 'XM4 5HQ'") > 0
If blnRet Then GoTo NextStep
If blnCancel Then GoTo EndRoutine
NextStep:
blnRet = False
Next Q
c) SQL Count(*)
Set db = CurrentDb
For Q = 1 To LC 'loop count
'check for non-zero count
With db.OpenRecordset("SELECT COUNT(*) FROM tblData WHERE Postcode = 'XM4 5HQ';")
blnRet = .Fields(0) > 0
.Close
End With
If blnRet Then GoTo NextStep
If blnCancel Then GoTo EndRoutine
NextStep:
blnRet = False
Next Q
d) SQL SELECT
Set db = CurrentDb
For Q = 1 To LC 'loop count
'check for non-zero record count
With db.OpenRecordset("SELECT ID FROM tblData WHERE Postcode = 'XM4 5HQ';")
blnRet = .RecordCount > 0
.Close
End With
If blnRet Then GoTo NextStep
If blnCancel Then GoTo EndRoutine
NextStep:
blnRet = False
Next Q
e) EXISTS
Set db = CurrentDb
For Q = 1 To LC 'loop count
'check for non-zero record count
With db.OpenRecordset("SELECT T1.ID FROM tblData AS T1 " & _
" WHERE (((Exists (SELECT 1 FROM tblData AS T2 WHERE T1.ID = T2.ID " & _
" AND T1.Postcode = 'XM4 5HQ' = True))<>False))")
blnRet = .RecordCount > 0
.Close
End With
If blnRet Then GoTo NextStep
If blnCancel Then GoTo EndRoutine
NextStep:
blnRet = False
Next Q
f) SELECT TOP 1
With db.OpenRecordset("SELECT TOP 1 tblData.ID FROM tblData WHERE Postcode = 'XM4 5HQ';")
blnRet = .RecordCount > 0
.Close
End With
Set db = CurrentDb
For Q = 1 To LC 'loop count
'check for non-zero record count
With db.OpenRecordset("SELECT TOP 1 tblData.ID FROM tblData WHERE Postcode = 'XM4 5HQ';")
blnRet = .RecordCount > 0
.Close
End With
If blnRet Then GoTo NextStep
If blnCancel Then GoTo EndRoutine
NextStep:
blnRet = False
Next Q
g) SEEK (Can only be used with indexed fields)
For Q = 1 To LC 'loop count
'seek match on indexed field
With db.OpenRecordset("tblData", dbOpenTable)
.Index = "Postcode"
.Seek "=", "XM4 5HQ"
blnRet = Not .NoMatch
.Close
End With
If blnRet Then GoTo NextStep
If blnCancel Then GoTo EndRoutine
NextStep:
blnRet = False
Next Q
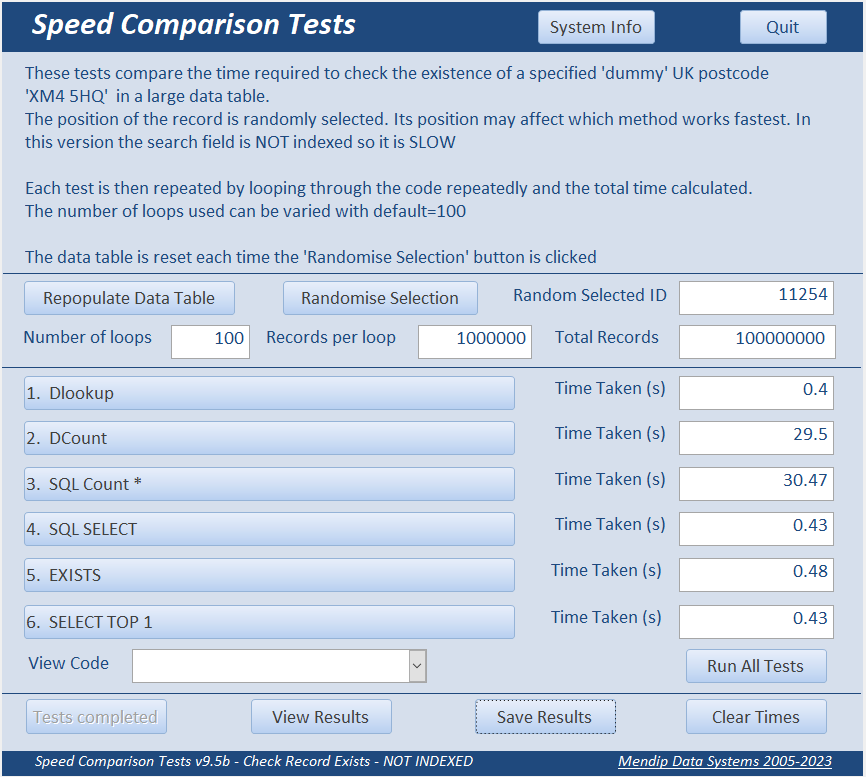
3. Search field NOT Indexed Return To Top
The search field (Postcode) is NOT INDEXED which makes the search time much SLOWER.
As the position of the search postcode record is randomly selected, its position affects the speed of certain tests
Each of the tests measure the time needed to detect the existence of the postcode ‘XM4 5HQ’.
Each test is then repeated by looping through the code multiple times
The number of loops used can be varied with default = 100.
So, in this case 1,000,000 records are looped through 100 times i.e. 100,000,000 records.
The position of the random record can be varied by clicking the 'Randomise Selection' button.
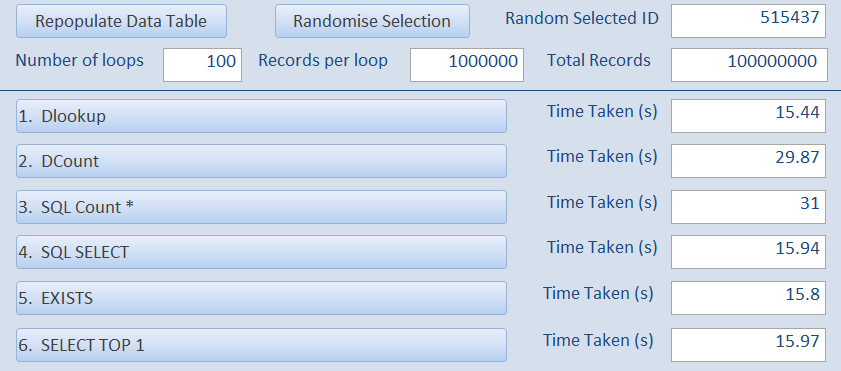
In the first example, the random record ID = 11254 – close to the start of the recordset.
In this case, DLookup and SQL SELECT are very fast with the DCount & SQL Count(*) MUCH slower.
This isn’t surprising as the two Count tests need to check the entire file.
The EXISTS and SELECT TOP 1 times are similar to those for DLookup and SQL SELECT as they all stop when a match is found.
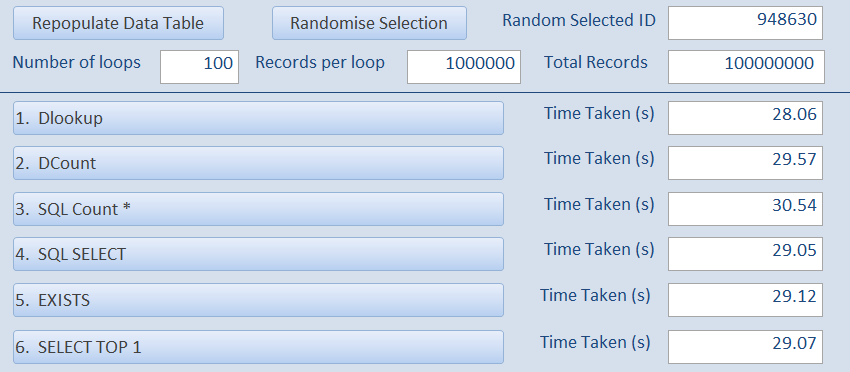
In the second example, the ID is 515437 – near the middle of the file.
As a result, it takes longer to detect the record using DLookup / SQL SELECT / EXISTS or SELECT TOP 1.
However, the two Count test results are almost the same as before
In the third example, the ID is 983734 – close to the end of the file
As a result, the times for the 6 tests are very similar but the two Count tests are still slightly slower
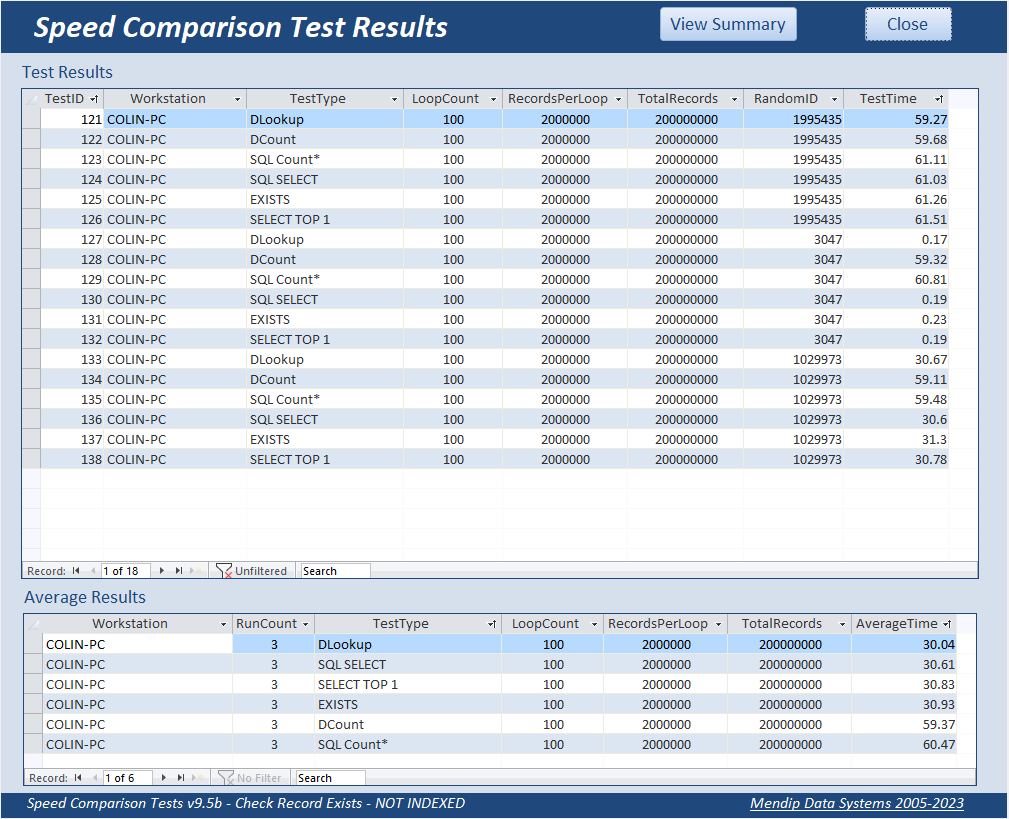
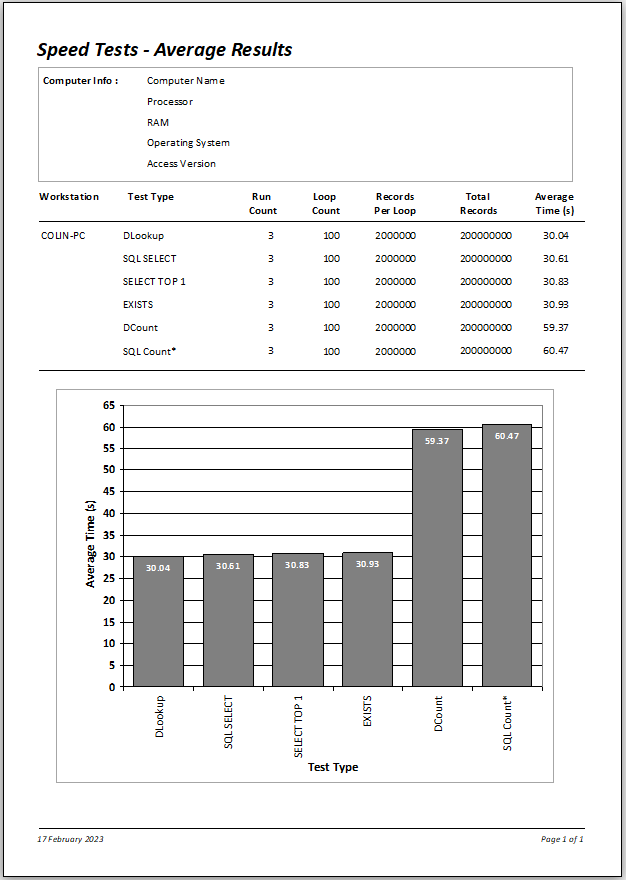
Here are the full results for 1 million records together with the average times:
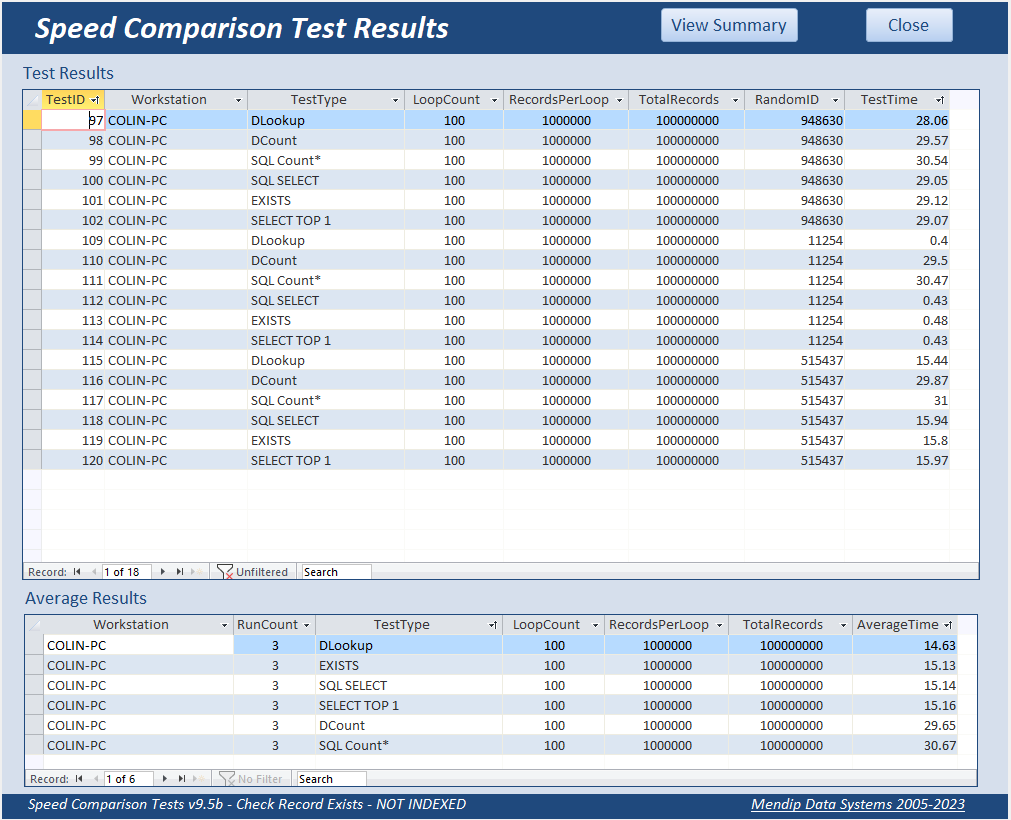
|
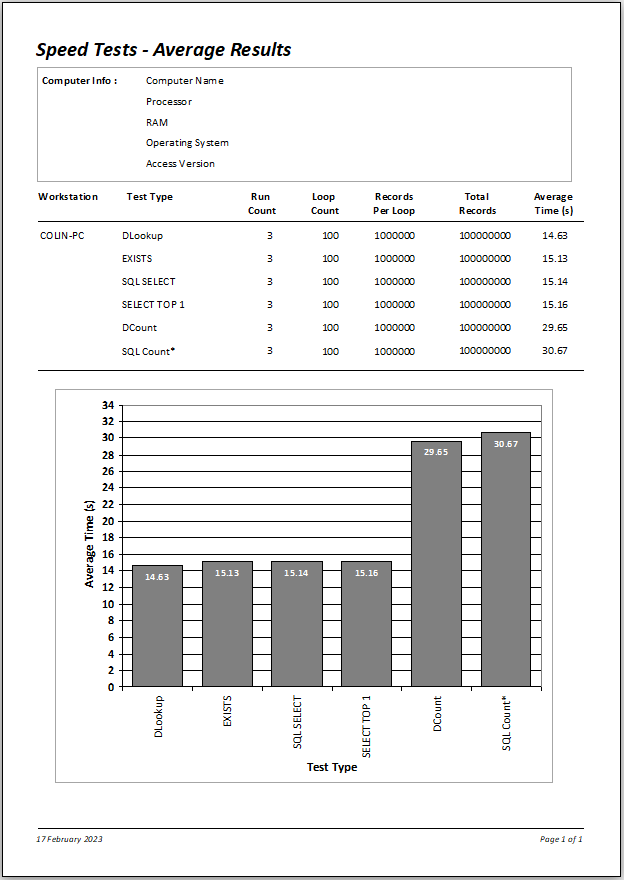
|
Next the number of records in the data table were doubled to 2 million
Here are the results where the search record was close to the start of the recordset.
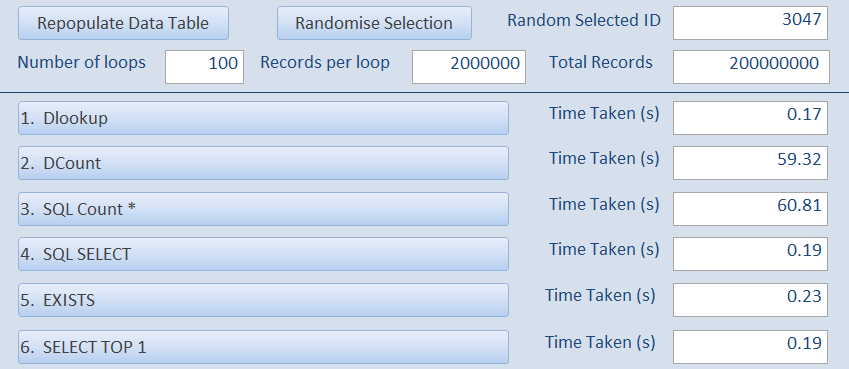
Once again where the ID value is near the end of the recordset
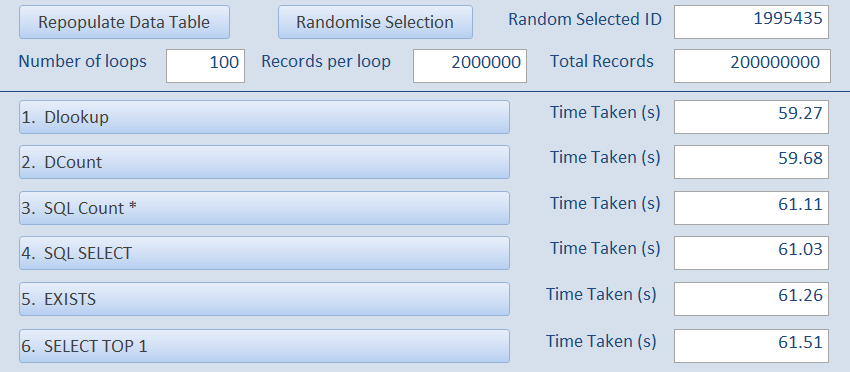
Here are the full results for the larger recordset of 2 million records
|
|
To a certain extent, the most effective method depends on the position of the record being checked (which will of course be unknown!).
Overall, using DLookup and SQL SELECT give very similar outcomes to each other, as do DCount and SQLCount(*)
However, the two Count methods are ALWAYS SLOWER for fields that are NOT INDEXED
The EXISTS and SELECT TOP 1 methods give very similar times to those for DLookup and SQL SELECT. Perhaps surprisingly, DLookup is the fastest (just)
4. Indexed Search Field Return To Top
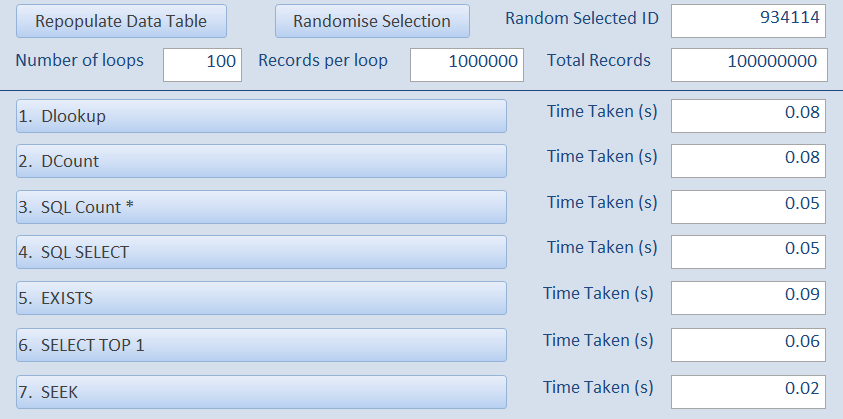
For comparison, the first test is IDENTICAL to that used in the original non-indexed example but with the additional SEEK test.
i.e. 1 million records in tblData and 100 loops in the speed tests.
The results are shown below left (together with the equivalent results from the first non-indexed test on the right)
INDEXED
|
NOT INDEXED
|
All INDEXED tests are VERY FAST – approximately 250x faster due to the effect of INDEXING
The SEEK test was by far the fastest with the EXISTS test (using a subquery) the slowest
The tests were then repeated using 1000 loops instead of 100:
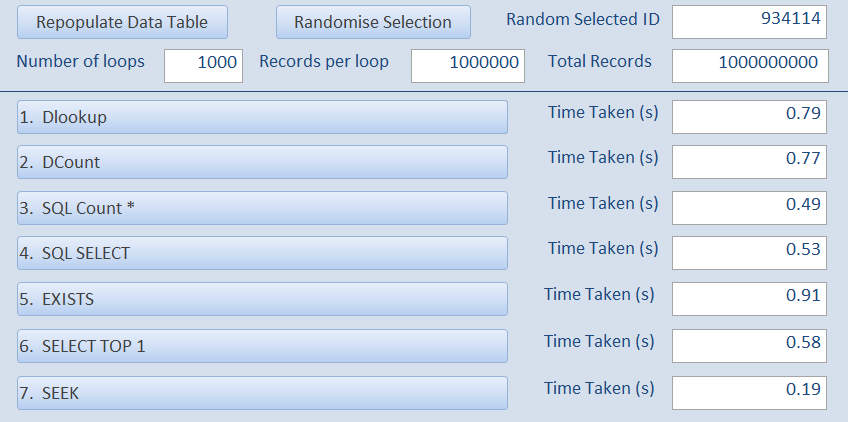
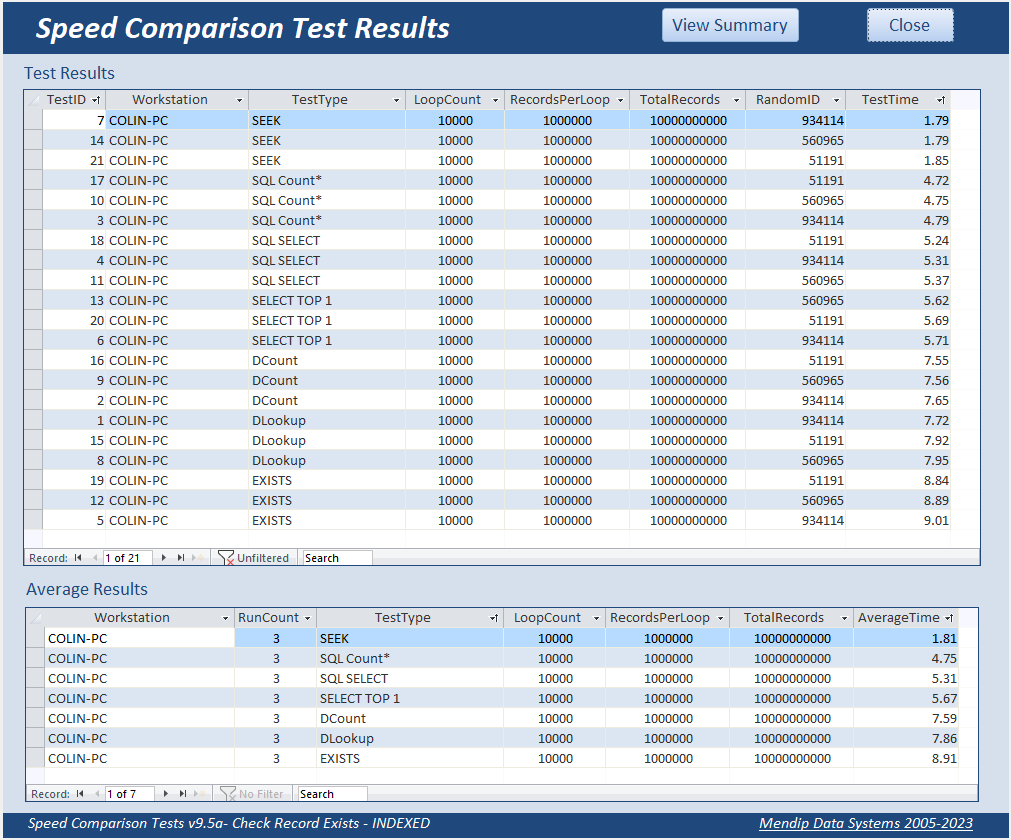
And once again using 10,000 loops of 1 million records
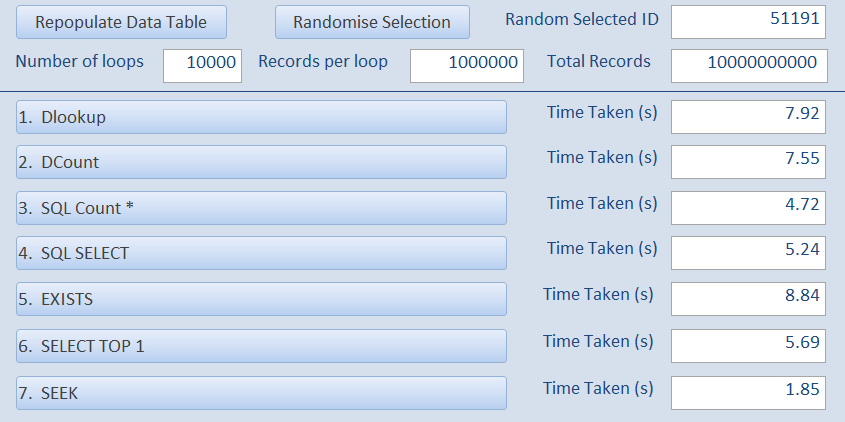
i.e. a total of 10 thousand million records checked... with all times between 2 and 9 seconds!
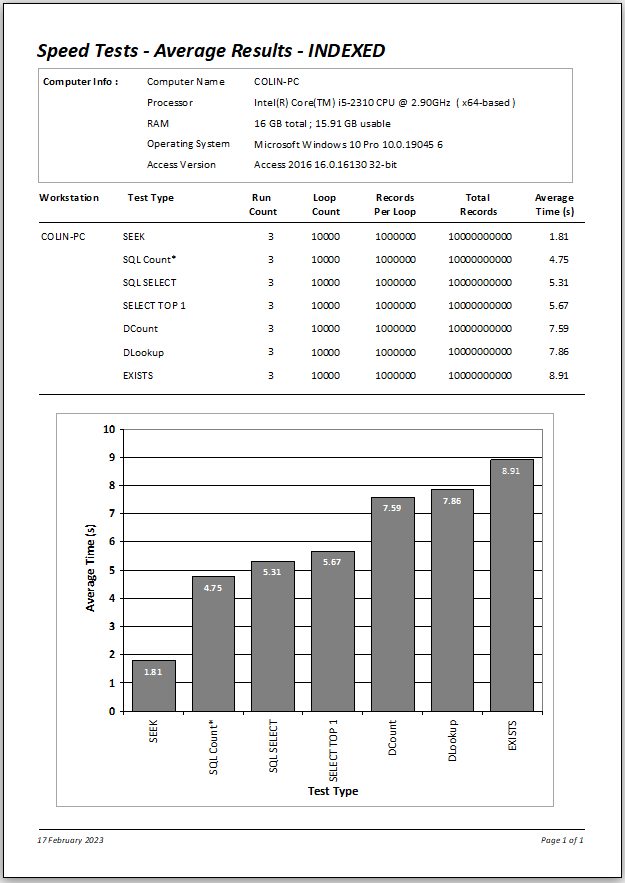
Although all times were extremely fast, EXISTS was slowest at just under 9 seconds with the two domain functions DLookup & DCount being slightly faster at a little under 8 seconds.
At less than 5 seconds, SQL Count was slightly faster than SQL SELECT or SELECT TOP 1 (both between 5 & 6 seconds).
However using SEEK is again by far the fastest, taking less than 2 seconds to complete
All times are fast because Access is searching the saved INDEXES so it doesn’t need to search the entire file whichever method is used.
The time to check 1 million records in each loop is between 0.02 and 0.09 seconds!
Here is a summary of the results.
|
|
The tests were then run once more using an even larger dataset of 10 million records.
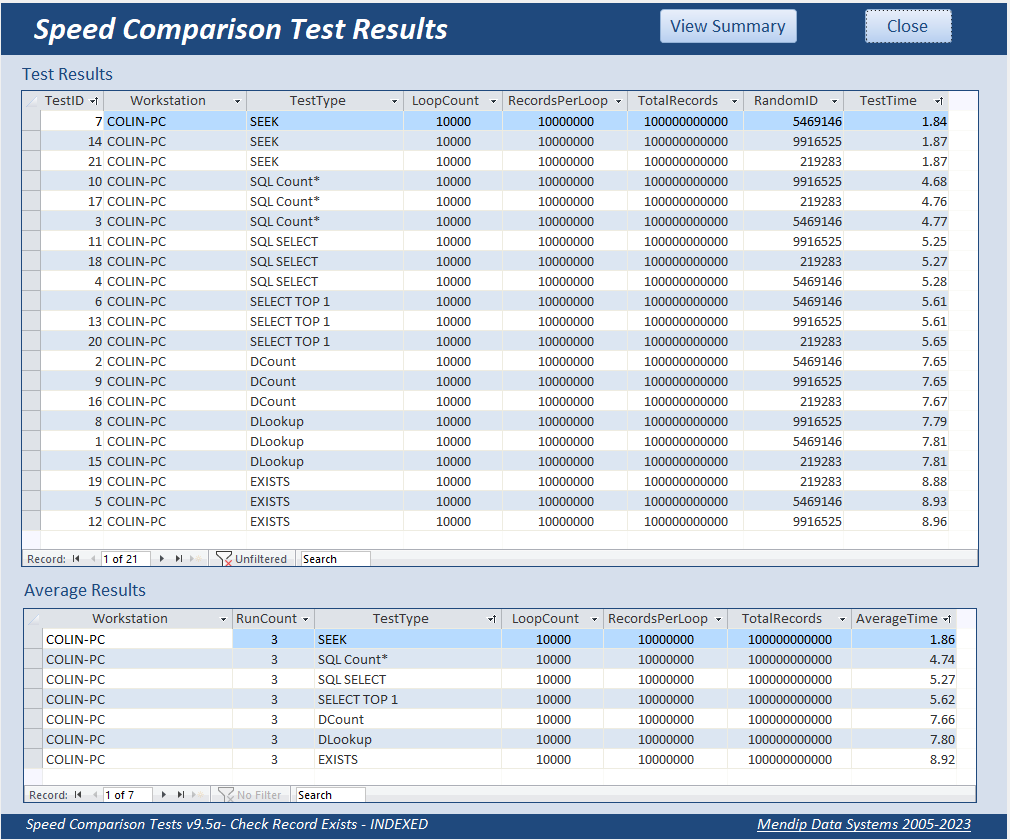
|
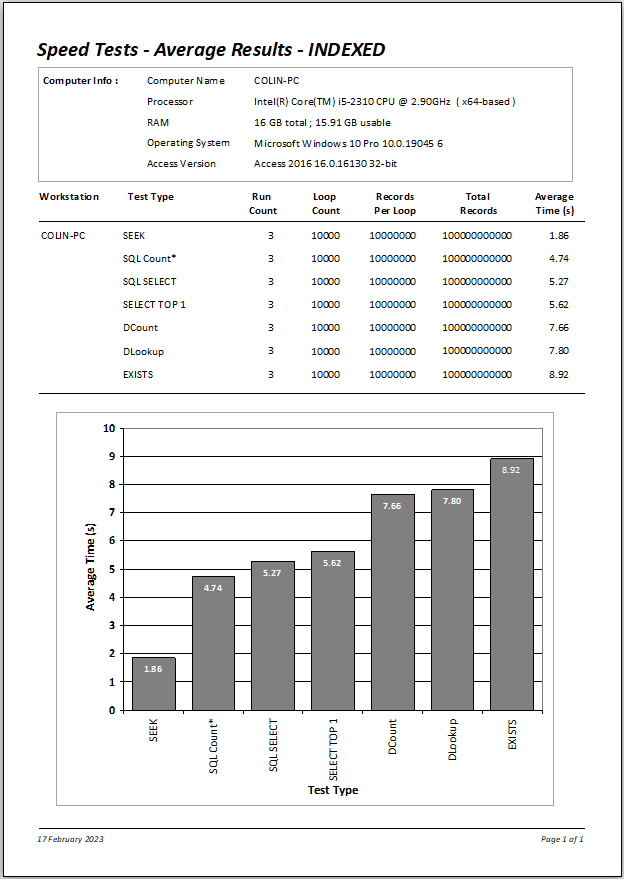
|
The outcomes for 10 million records are effectively IDENTICAL to those with 1 million records - between 2 and 9 seconds in each case.
The benefits of indexing become even more apparent the larger the dataset used.
Conversely, if your tables have only a few records, indexing provides minimal benefit
Apart from increased file size, there is another disadvantage of indexing.
Running action queries on an indexed field will take significantly longer (up to 50% more in tests).
This is because the index needs to be updated as well as the individual records
Although all methods are fast, using SEEK is by far the fastest approach. However, it is far less widely used than other methods. SEEK can only be used with indexed fields and the approach cannot be used with linked tables
For more information, see the Microsoft Help article: Recordset.Seek method (DAO)
NOTE: This quote is from the above help article:
You can't use the Seek method on a linked table because you can't open linked tables as table-type Recordset objects.
However, if you use the OpenDatabase method to directly open an installable ISAM (non-ODBC) database, you can use Seek on tables in that database.
The two domain functions and EXISTS are the slowest methods in these tests
If SEEK is not possible in your situation, any of SQL Count, SQL SELECT or SELECT TOP 1 will give excellent results
NOTE:
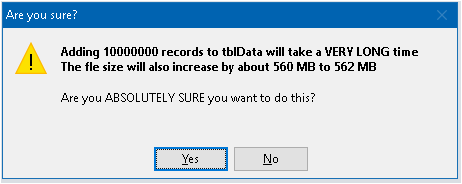
Creating huge datasets takes an EXTREMELY long time and significantly increases file size.
This 10 million recordset took about 40 minutes to complete. The file became almost 760 MB bigger
If you try to create a very large dataset using the example app, you will be warned about the implications.
As the Access file size limit is 2GB, the MAXIMUM possible number of records is around 30 million.
I tested this and the file was well over 1.9 GB before compacting.
To prevent the risk of hitting the file size limit and consequent datafile corruption, the application will not allow you to add more than 25,000,000 records.
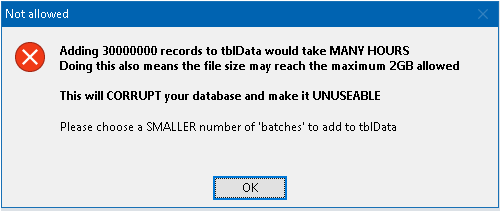
If you really must try the largest dataset allowed, you need be aware that it will take SEVERAL hours to create that many records.
5. Downloads Return To Top
Click to download:
Speed Comparison tests 9.5A - INDEXED Approx 1.8 MB (zipped)
Speed Comparison Tests 9.5B - NOT INDEXED Approx 1.6 MB (zipped)
6. Feedback Return To Top
Please use the contact form below to let me know whether you found this article useful or if you have any questions/comments.
Do let me know if there are any errors
Please also consider making a donation towards the costs of maintaining this website. Thank you
Colin Riddington Mendip Data Systems Last Updated 17 Feb 2023
Return to Speed Test List
Page 7
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Return to Top